

一、先明确:本地 14900K “跑不动” 上亿网格的核心瓶颈
Intel 14900K(16 核 32 线程,主频最高 5.8GHz)虽是消费级顶级 CPU,但面对 “上亿网格” 仿真(常见于流体力学、结构力学等领域,如 CFD、FEM),其硬件架构和资源规模存在3 个不可逾越的短板,直接导致 “无法启动” 或 “启动后卡死”:
1. 算力瓶颈:“单芯片多核” vs “上亿网格的计算量”
上亿网格的仿真,本质是对每个网格单元求解 “偏微分方程”(如 Navier-Stokes 方程、弹性力学方程),且网格间存在强耦合(需频繁交换边界数据)
假设 1 个网格单元每时间步需 100 次浮点运算,1 亿网格每步就是10^10 次运算;若模拟 1000 个时间步,总计算量达10^13 次运算。
14900K 满负载(32 线程)的理论算力约500 GFLOPS(10^9 次 / 秒) ,仅完成 10^13 次运算就需约 20000 秒(近 6 小时) ,且这还未包含 “数据传输、边界耦合、IO 写入” 等耗时 —— 实际可能需数周甚至数月,远超 “可接受范围”,且中途极易因 CPU 过热、系统资源不足崩溃。
2. 内存瓶颈:“消费级内存” vs “上亿网格的存储需求”
仿真过程中,需将 “网格坐标、物理参数(密度 / 速度 / 应力)、边界条件、中间计算结果” 全部加载到内存(RAM)中,否则会频繁触发 “内存 - 硬盘交换”(Swap),速度骤降(硬盘速度比内存慢 1000 倍以上):
上亿网格的内存占用取决于精度:单精度浮点数每网格占 4 字节,1 亿网格仅存储坐标就需 120GB,再加物理参数会翻倍。
14900K 的主板通常支持最大128GB DDR5 内存(且需 4 条 32GB 内存,成本极高),即使插满 128GB,也无法装下 “上亿网格的全量数据”—— 必然触发 Swap,导致计算卡死(硬盘疯狂读写但进度不动)。
3. 架构瓶颈:“单节点” vs “分布式并行”
本地 14900K 是 “单 CPU + 单节点” 架构,而上亿网格仿真需要 “分布式内存并行”(将任务拆分到多个 CPU / 节点,各自计算后交换数据):
二、超算三层并行与硬件生态协同
超算能突破本地瓶颈,核心是通过“任务拆分(并行算法)+ 硬件加速(多核 / 高速互联)+ 资源调度(集群管理)”的三层协同,将任务拆解为 “可并行执行的小任务”,具体逻辑如下:
1. 第一层:仿真软件的 “分布式并行算法”—— 把 “上亿网格” 拆成 “上千份小任务”
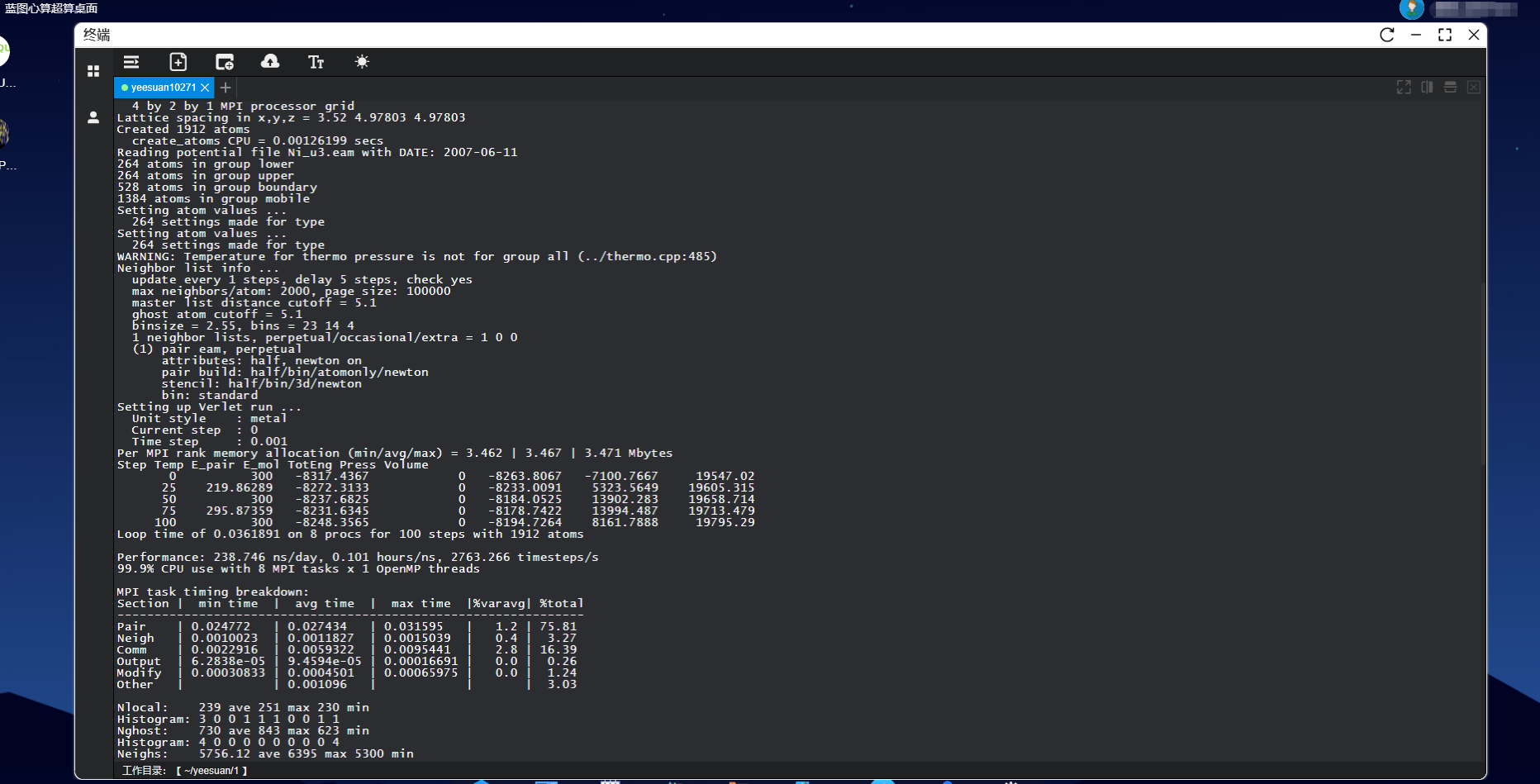
超算运行的仿真软件(如 ANSYS Fluent、ABAQUS、OpenFOAM)均支持MPI(消息传递接口)分布式并行,这是 “上千核协同计算” 的前提
2. 第二层:超算硬件生态的 “性能加持”—— 让 “并行任务” 跑更快
超算的 “上千核(通常是数十个节点,每个节点 56 核如 6258R)+ 高速互联 + 大内存”,为并行计算提供了 “硬件基础”,直接放大并行效率:
CPU 算力:从 “单芯片” 到 “集群多核”
内存:从 “单节点 128GB” 到 “集群 TB 级内存”
超算每个节点 192GB 内存,10 个节点就是 1.92TB 内存 —— 轻松装下 “上亿网格的全量数据”,且每个节点的 DDR4 内存带宽达200GB/s 以上(是 14900K DDR5 带宽的 2-3 倍),确保 “核 - 内存” 数据传输速度跟得上计算速度,避免 “核等数据”。
网络:100Gbps IB 网 —— 解决 “分布式数据交换瓶颈”
上千核分布在数十个节点上,节点间需频繁交换 “边界数据、全局结果”,100Gbps IB 网的带宽是本地千兆以太网(1Gbps)的 100 倍,延迟是其 1/100—— 假设每个节点每步需交换 1GB 数据,IB 网仅需 0.08 秒,而以太网需 8 秒,前者几乎无等待,后者会让并行效率骤降。
3. 第三层:超算的 “资源调度与优化”—— 确保 “硬件不浪费”
超算不仅是 “一堆高性能硬件的堆砌”,还通过集群管理系统(如 Slurm、PBS) 和编译优化,让硬件性能最大化:
资源独占调度:超算会为你的 “上千核任务” 分配 “专属节点”,避免其他任务抢占 CPU、内存、网络资源 —— 而本地 14900K 可能同时运行系统进程、软件后台,算力被分流。
针对性编译优化:超算的仿真软件通常用 Intel oneAPI、GCC 高版本编译器编译,启用 “针对 Intel Xeon Gold 的 AVX512 指令集优化”“MPI 通信优化”
IO 优化:上亿网格的仿真会生成 GB 级甚至 TB 级的结果文件(如轨迹文件、日志文件),超算配备并行文件系统(如 Lustre、GPFS) ,支持上千个核同时读写文件(本地硬盘仅支持单线程读写),避免 “计算快但写文件慢” 的瓶颈。